

ChatGPT doesn't understand Chinese well. Is there hope?
A Look into Text Corpus, the Training Data that Matters to AI's Accuracy, in the Chinese World

Chat GPT has been making waves in China's scientific and technological innovation circle, and its popularity has spread throughout society. However, when it comes to Chinese language processing, ChatGPT often falls short. With much debate surrounding China's ability to develop its own ChatGPT, the size of the training data has been a factor often ignored in these discussions. While not the sole determining factor, the size of the training data greatly impacts the performance of Large Language Models (LLMs) like the GPT model, which is used in many of the recent popular AI products. The question remains: Can China catch up with Silicon Valley in this AI competition, or will the lack of quality training data continue to be a roadblock for ChatGPT's success in the Chinese world?
LLMs were significantly undertrained in Chinese data
Different public sources reported that most of the LLMs use significantly more English training data than non-English data. For example, OpenAI reports that 181 billion English words and 190 million Chinese words were used to train GPT3, which was 900x in difference. These drastic differences lead to inaccuracy when users request LLM to output Chinese.
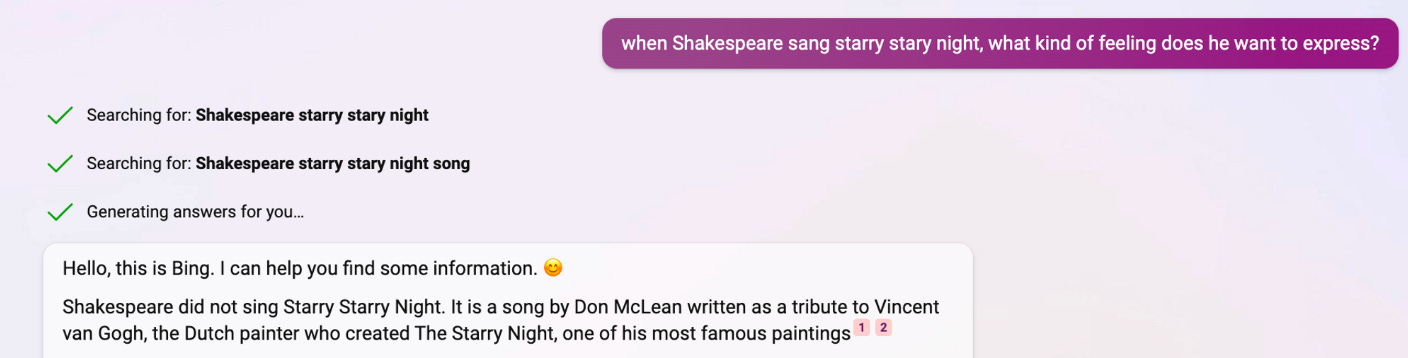
For example, I asked Bing AI (based on GPT-4) similar types of questions where I linked an artwork to the wrong artist in both Chinese and English. Bing AI only detected false logic in English and followed my false logic in Chinese.

In another example, ChatGPT gave a made-up CV when asked about a professor at the Beijing Institute of Technology.

China's Own LLMs Won't Change the Situation
The lack of training data in Chinese hence led to higher inaccuracy of GPT models. One may then ask, can China-focused models increase the weight of Chinese training data to address such a situation? The short answer is no.
One case in point is the first LLM model by large Chinese tech company, Baidu's Ernie. Ernie was released on March 16, 2023. Early test users found inaccurate output in many cases, which may have been caused by the model's lack of understanding of original Chinese text. For instance,
